Hypothesis: The Social Annotation Platform
That Gets Students Reading Again
Students aren’t reading. Discussion boards are dead zones. AI shortcuts are everywhere. Hypothesis — the market-leading social annotation platform — transforms passive assignments into active, collaborative learning. Built for higher education. Integrated directly into your LMS.
How Does Hypothesis Social Annotation Work?


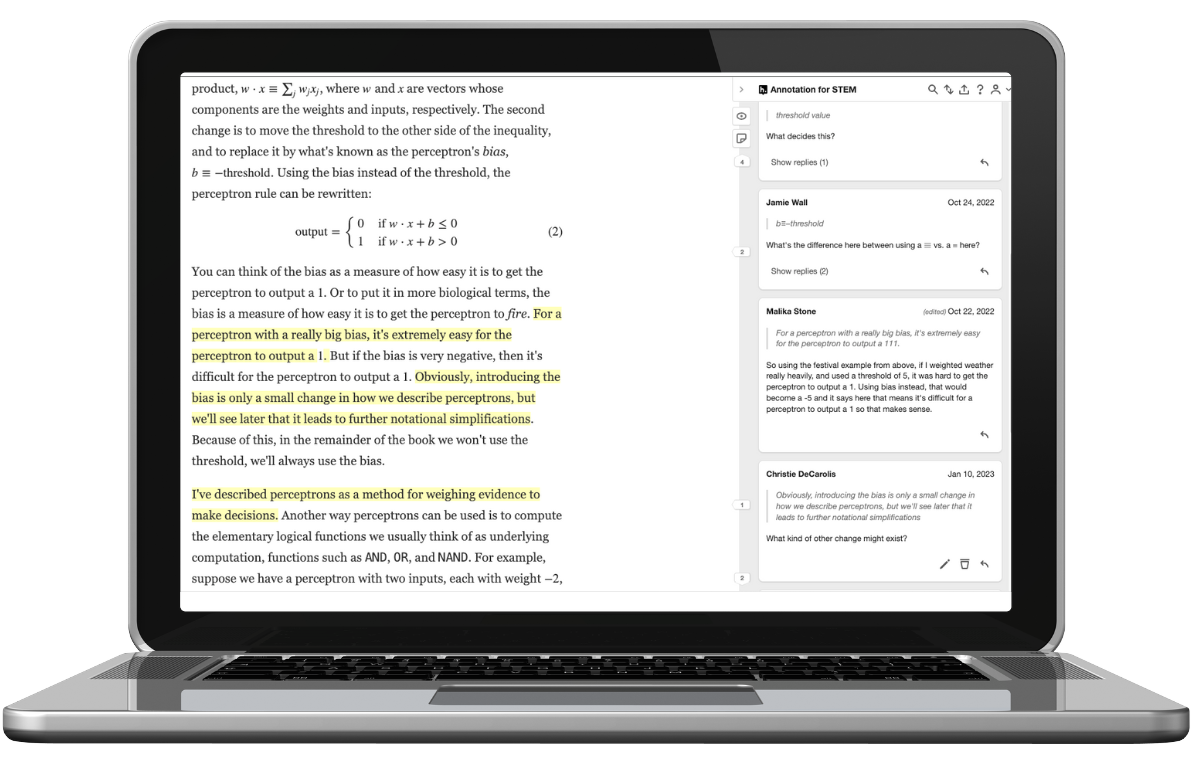
Comment and highlight directly over content.
Students, faculty, and colleagues can highlight and comment directly on online articles, websites, videos, and more without switching platforms.


Turn Annotations into Discussions.
Students, faculty, and teams can share ideas, ask questions, provide insights and respond directly to annotations. Creating a dialogue directly over content.


Tag Other Users for Increased Collaboration.
Faculty, students, and teams can engage more deeply by tagging peers directly in annotations, triggering notifications and encouraging students to revisit course materials and participate in ongoing discussions.
Why 300+ Institutions Choose Hypothesis
Human Centered Learning in the Age of AI
Hypothesis is built on a simple belief: real learning happens when students engage directly with ideas — not when they summarize them for an AI.
Students are turning to AI to shortcut the reading and thinking that higher education depends on. Hypothesis restores what matters: real engagement with course materials, deeper critical reading, and authentic dialogue between students and instructors. Instead of policing AI, faculty can create learning environments where students actually read, think, and contribute.
Explore how Hypothesis supports AI literacy:
Stronger Student Outcomes
Hypothesis delivers measurable results. Institutions using Hypothesis report a 32% increase in class retention, doubled comprehension scores, and a 24% improvement in student grades.
See the impact on student success:
Workforce-Ready Skills
Hypothesis prepares students for the modern workplace by teaching them to read critically, communicate clearly, and collaborate in real time — the same skills employers demand.
Discover how Hypothesis builds career readiness:
Transforming the Teaching & Learning Experience
Learn how educators are using Hypothesis to improve outcomes, strengthen retention, and prepare students with real-world skills.
Hypothesis Integrates Directly Into Your LMS — No Extra Tools Required
Hypothesis is the only social annotation platform that lives inside your existing LMS workflow.No extra logins. No new software for students to learn. Instructors set up assignments in minutes, interact with students directly over course materials, and track engagement through the Hypothesis reporting dashboard — all without leaving Canvas, Blackboard, Moodle, or D2L.
The Hypothesis Impact
Proven Success with Hypothesis
What Can Be Annotated with Hypothesis?
Hypothesis works seamlessly across every content type your students encounter:
![]()
Webpages – Annotate articles, research, and course readings right where you find them—directly in your browser.
![]()
Online PDFs – Highlight and annotate papers, readings, and handouts directly in the document.
![]()
Videos – Annotate videos with highlights, questions, and comments as you watch.
![]()
Images – Add pins and notes to diagrams, graphs, music scores, and visuals for deeper understanding.
![]()
eTexts – Turn digital textbooks into interactive spaces for highlights and conversation, Including VitalSource eTexts, directly within the platform.
![]()
Online Articles – Highlight and annotate scholarly readings, including JSTOR articles directly within the platform.
Join 300+ Institutions Already Using Hypothesis
Hypothesis is the social annotation platform built for higher education — and it’s ready to work inside your LMS today. Join hundreds of institutions already transforming the way students read, think, and learn.