Originally posted at Pundit by Francesca Di Donato
The diffusion and the public endorsement of data FAIRness has been rapid. The FAIR Data Principles were were published in late 2014 and early 2015. In 2015 at their summit in Japan, the European Council and the G7 adopted Open Science and the reusability of research data as a priority, thus providing fertile ground for their uptake. Finally, the European Commission with Big Data to Knowledge (BD2K), Science Europe, and the G20 in the 2016 Hangzhou summit al endorsed data FAIRNESS (Mons et al, 2017).
Despite this, the actual numbers about data FAIRness are still insufficient and disappointing: in his recent LIBER webinar “Are FAIR Data Principles FAIR?” Alastair Dunning reported some data that highlighted that practice is still far from theory. Considering the number of open repositories, 41% of their data are findable and 76% are accessible, but only 38% are interoperable and 18% reusable. In particular, 49% of the repositories do not assign a persistent unique identifier to data sets. So compliance is not high. Some of the principles are easy to measure, others are much more subjective. There are still many open issues and the definition itself is open to interpretation, as explained by its promoters here.
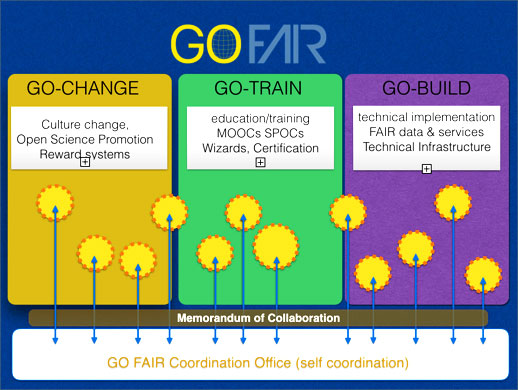
The Global Open (GO) FAIR Initiative is among the initiatives aiming at putting Open Science into practice: a bottom-up initiative to start working in a trusted environment where public and private sector partners can deposit, find, access, exchange and reuse each other’s data, workflow and other research objects.
There are many issues to be addressed, with more social limitations and obstacles than technological ones. In practice, the GO FAIR implementation approach is based on three interactive processes/pillars:
The first pillar is go change: a cultural change is needed, where open science and the principles of data findability, interoperability, accessibility and reusability are a common way of conducting science.
Cultural change can be achieved through training focused on locating, creating, maintaining, and sustaining the required core data expertise.
The aim of the second pillar, go train, is to have core certified data experts and to have in each Member State and for each discipline at least one certified institute to support implementation of Data Stewardship per discipline.
The last pillar, go build, deals with the need for interoperable and federated data infrastructures and the harmonization of standards, protocols, and services, which enable all researchers to deposit access and analyse scientific data across disciplines.
To have reusable annotations and graphs in a unique interoperable environment independently of both the client and the server people are using will be one of the main goals of the implementation network on annotation.
The GO FAIR Initiative is supported by the Annotating All Knowledge Coalition, Pundit and Hypothesis.
Read more about GO FAIR, access the full documentation, and fill in the survey to support the initiative.