How Annotation Enables Machine Learning
In Annotation-Powered Questionnaires we at Hypothesis previewed an app built to help the Credibility Coalition (CredCo) develop a set of indicators that bear on the credibility of news stories.
The first round of annotation is now done. The annotators were blinded from one another, but I’ve extracted and anonymized a small sample of their annotations to show what’s possible with this data.
Here’s one of the questions that the annotators answer by making highlights in news stories:
Do they [the authors] acknowledge uncertainty or the possibility that things might be otherwise? If so, highlight the relevant section(s).
I love this question! It’s my favorite among all the indicators proposed in the W3C draft Content Credibility Indicators Vocabulary (CCIV). Acknowledgement of uncertainty is one of the core principles of rational inquiry. I’m more inclined to trust news sources that signal their credibility by upholding that principle, If news aggregators can detect and process that signal at scale, they can help me separate the wheat from the chaff. But how will we teach them to do that?
Machine learning systems work, broadly, with two kinds of data: unlabeled and labeled. We’ll focus here on labeled data. The data, in this case, are labeled highlights in news stories. The highlights are created by human annotators in response to the prompt: “Please highlight examples of acknowledgement of uncertainty.”
Follow this link to see what annotators think are examples of acknowledgement of uncertainty. Here’s a partial view:
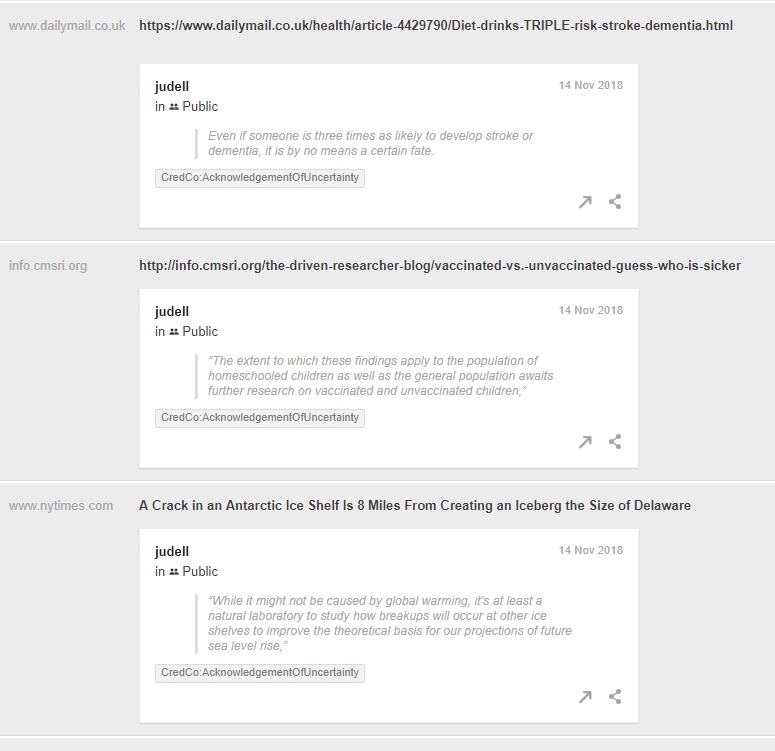
You’re not seeing the original annotations. Those live in private layers shared, by permission, with the CredCo team. For this view I’ve extracted, anonymized, and republished the original annotations.
I would agree that the annotations shown in the screenshot are valid examples of acknowledgement of uncertainty. But if you explore the full set of answers you’ll find some that clearly are not. Because the responses live in the annotation layer, anchored to highlights in the news stories, the team can discuss these questionable cases in context, and agree to tag some as invalid examples.
Once the team has reviewed and processed the responses, we can feed them to machine learning systems that will (we hope!) get good at recognizing other examples of acknowledgement of uncertainty, or of other credibility indicators. This is the same two-step strategy we’re pursuing in another domain, biocuration (see SciBot):
1. Use people to label and curate examples.
2. Use machines to learn from the examples and scale the curation.
Step 1 is a real sweet spot for annotation. What about Step 2? We’ve yet to see how well our results so far will support machine learning, but I’m keen to find out and will report back when we know more.
This post also appears on the Misinfocon blog.