Hypothesis for Web Developers
We’ve written a lot here about Hypothesis for teachers and students, for publishers, for fact checkers, for reviewers and curators of scholarly literature, and for any individual or team that gathers and organizes pieces of web content. One constituency we haven’t addressed, though, is web developers.
Annotation enlarges the web’s surface area. Formerly we could locate resources identified by billions of URLs. Now we can also locate segments defined within those billions of resources. It was already true that the emergent properties of the URL-addressable web continued to surprise me on a regular basis. Nowadays annotation delivers even more delightful surprises. Here’s the latest one, and it’s a real mind-expander.
I’m working on a form-filling tool. A user of the tool will visit instances of many different types of vendor catalog pages, and will be required to extract a few pieces of information from each instance and transfer them to the form. Ideally the bar would be higher, and the user would be required to extract and transfer more information, but that would entail more work than the user can reasonably be expected to do, and higher risk of copy/paste error than is tolerable.
What to do? Enter Hypothesis. When you annotate a selection in a web page, Hypothesis saves a variety of selectors used to anchor the selection to the page. There’s TextQuoteSelector, which is the most fundamental. It captures the selection plus surrounding context. But that’s a fallback, in case several other anchoring strategies fail. The selector of first resort is RangeSelector, which uses XPath expressions that identify the DOM node where the selection begins and ends. These are often the same, but if the selection crosses node boundaries — for example, when the selected text includes span or link tags — they can differ.
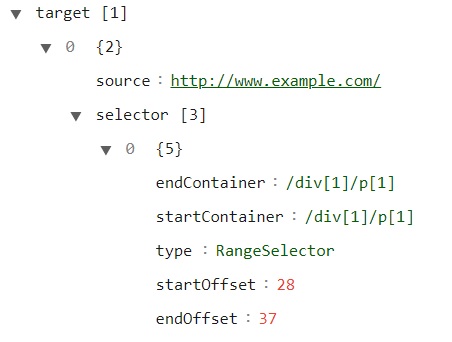
If you’re a normal user of Hypothesis, that’s an unimportant detail. But if you’re building the form-filling tool I’ve described, it’s the enabler for a magically powerful technique. Let’s say there are 25 different vendor catalogs, each of which has thousands of pages subject to the optimization I’m about to describe. Here’s the technique. Annotate one representative sample from each of the 25 catalogs. For each field that you want to capture in the form-filler, highlight the item of data and tag it with the name that field will have in the form. Hypothesis obligingly captures the XPath address of that piece of data, which you can retrieve from the Hypothesis API. That XPath address can now locate the corresponding piece of data in any of thousands of instances of that vendor’s page, since they’re all built from the same template.
Could you do the same thing without Hypothesis? Sure. You could visit a sample of each of the 25 vendor catalogs, and manually capture the XPath address for each of the fields. (In Chromium-based browsers, you can do that by inspecting the DOM and using the Copy as XPath tool.) Then you’d put each captured XPath into a database, keyed to the vendor’s domain and the fieldname of the item.
But there’s no need! A tagged annotation in Hypothesis does all this for you. Your selection captures the domain and the XPath, your tag identifies the field, the Hypothesis database is the database you pull these ingredients from when a user runs an instance of the form-filler. It’s a huge optimization.
Other pleasant surprises like this will surely appear. I can’t predict what they’ll be, for the same reason I still can’t predict how the web itself will continue to pleasantly surprise me. The web of linked resources produces a steady flow of emergent capabilities. The web of linked segments increases that flow.