Try our prototype OCR tool
Here: http://docdrop.org/ocr
While some PDFs may contain only images, you may find yourself working with a PDF which is meant to have selectable text, but none of the text is selectable. In the latter case you can use OCR technology to create a selectable text layer in these PDFs.
There are many free and paid OCR tools on the internet; below we describe how to use our own prototype OCR tool.
To OCR a PDF:
- Open http://docdrop.org/ocr
- Drag a file on to the docdrop page or click the docdrop page and select the file from your computer.
- Click “Run OCR”.
- If your PDF already has selectable text but it is garbled, incomplete, or otherwise broken you can try the “Force OCR” button to create a new text layer in the document.
- Download the resulting PDF and use it in Hypothesis.
What is OCR?
OCR, or Optical Character Recognition, is a process where software converts images of text into a machine-readable format. Web browsers and apps like Hypothesis need this machine-readable format in order to recognize and select text within the document.
OCR-optimized documents are beneficial to blind and visually impaired readers, as OCR allows screen readers and other assistive technology to interact with the text. Working with OCR-optimized documents is a best practice whether or not you are annotating with Hypothesis.
How do I know whether my PDF is OCRed?
If you can easily select a line of text and then copy and paste it elsewhere, and the pasted text is properly formatted, your PDF is OCR-optimized and you can start annotating.
You will need to apply OCR technology to your PDF if any of the following is true:
- You are unable to select any text
- You can select text, but it is difficult to get only the text you want
- You can select text, but it is “garbled” or poorly formatted once you copy and paste it elsewhere
- Someone who uses screen reader technology has indicated the PDF is difficult to read
We’ve included directions on how to use a tool called docdrop at the top of this article. Below you’ll find some other options you can use to OCR a document.
How to OCR a PDF using Acrobat
To use the tutorials below, you will need to have Adobe Acrobat installed. If you do not have an Adobe subscription, you might consider downloading a free trial of Acrobat or checking with your school, institutional, or local library.
Here are written instructions for using Adobe Acrobat’s OCR technology, or you can watch a short video tutorial below:
How to OCR a PDF using PDFelement
PDFelement (https://pdf.wondershare.net/) is another tool that can convert an image-only PDF to a text-based PDF that can be annotated. When you open an image-only PDF in PDFelement, the program says:
! We detect this is a scanned PDF, and recommend you perform OCR, which enables you to copy, edit, and search texts from scanned PDF documents. [Perform OCR]
When you click Perform OCR your options are:
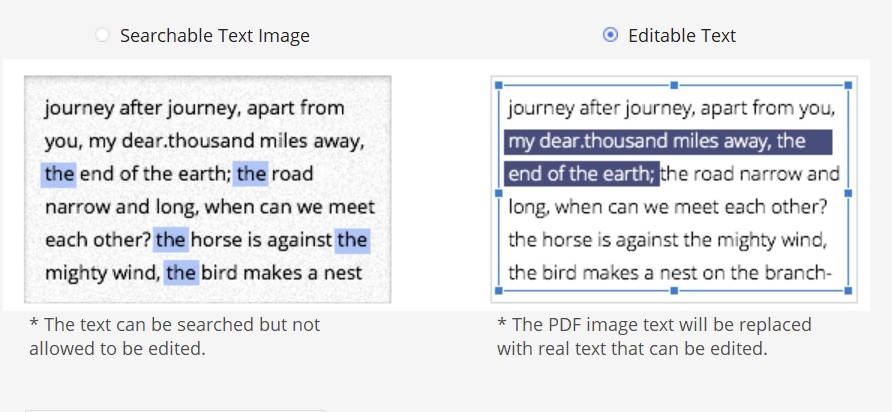
Here are samples of each:

For our purposes, “searchable” means that the text you read is the text that appears on the scanned page, whereas the text you select is rendered into a hidden layer on the web page. And “editable” means that the text on the scanned page is hidden, what you read is the same text that is rendered — now visibly — on the web page.
PDFelement recommends the “editable” (visible text) mode, and that’s the one that works best with Hypothesis. For most readers and for most documents, text rendered in a browser-based font will be more readable than the text in the scanned image.
Why might you prefer the “searchable” (invisible text) mode? When text is unrecognizable, the underlying image will be more readable, as above for the phrase “too often … effective parenting.” Note, however that the text you select for annotation will be the same in both cases. In this example here’s the text that was actually recognized:
“too often the demand to empower mothers is recast as a strategy for more etfective-fiarentrng.”
Or you might prefer the underlying text because it more faithfully represents the original document.
If you do choose “searchable” (invisible text) mode for such reasons, please note that while you can still use Hypothesis to annotate such documents, your selections will lose the spaces between words. If the selection is “too often the demand,” the quote captured in an annotation will be “toooftenthedemand.”